1. 액세스란? ★★★
DBMS에 저장되어 있는 데이터를 찾기 위한 과정이다.
행의 정보는 'ROWID' 라는 주소에 저장되어 있다.
- 테이블 액세스: 테이블안의 하나의 행마다 ROW_ID 가 존재하는데, 이 ROW_ID의 컬럼 값은 행의 위치를 알려주며,
행의 위치에서 다른 컬럼의 값도 가져올 수 있다.
- 인텍스 액세스: ROOT 에서부터 연결되어 있는 리프 블록까지의 타고 내려가면서 ROW_ID 을 찾는다.
ROW_ID을 이용하여 테이블을 찾는 과정을 찾는다. 이를 random access 라고 한다.
참고 : https://sewonzzang.tistory.com/34
[SQL] 인덱스(Index) - (1) 미리보는 인덱스 튜닝
sql관련 글들은 친절한SQL튜닝 책을 보며 학습중인 내용들이 작성될 것입니다. 최근에 쿼리 과제를 진행한 적이 있었는데, 발표는 하지 않아 피드백을 받지 못했지만 효율성을 따지지 않고 문제
sewonzzang.tistory.com
그럼 어떤 경우에 테이블 인덱스 액세스를 선택할까?
- 테이블에 저장되어 있는 대부분의 정보를 출력하는 경우 : 테이블 액세스 사용
- 테이블에 저장되어 있는 일부분의 정보를 출력하는 경우 : 인덱스 액세스 사용
2. 테이블 액세스 종류
- Full Table Scan
explain plan for
select * from orders;
select * from table(DBMS_xplan.display);
Plan hash value: 1275100350
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 51290 | 11M| 480 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| ORDERS | 51290 | 11M| 480 (1)| 00:00:01 |
----------------------------------------------------------------------------
#인덱스가 있음에도 access full을 한다
#where 절에 구성 컬럼에 있어야지 인덱스를 사용한다.
### DBMS_xplan.display 제대로 외워야함!! 시험에 나옴
Full table 을 사용하는 이유는?
1) 마땅히 사용할 인덱스가 없는 경우
2) 선택도가 높은 경우(예: 성별)
3) full table hint 가 사용되는 경우
- Table access by row_id
index scan 사용시 table access by index rowid 가 사용된 경우 = random access 과정이라 성능상 악영향
explain plan for
select * from orders where row_id = 39501;
select * from table(DBMS_xplan.display);
Plan hash value: 2054213856
---------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 227 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| ORDERS | 1 | 227 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | IDX_ORDERS_ROW_ID | 1 | | 1 (0)| 00:00:01 |
---------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ROW_ID"=39501)
random access

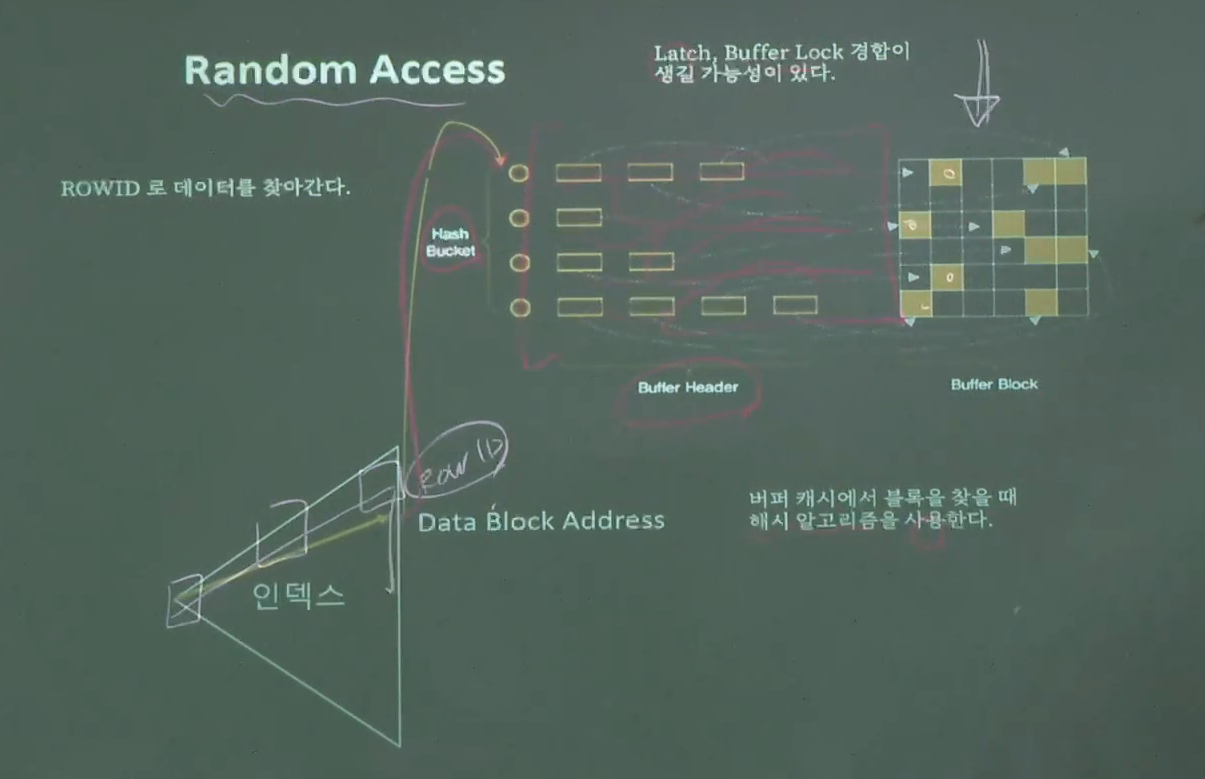
buffer block 에서도 없을 경우 disk 로도 가기 때문에 속도가 떨어진다.
- Index range scan
Index 를 사용하는 가장 중요한 scan 방식
선택도가 낮으면 옵티마이저가 index range scan 을 사용하나 선택도가 높은 경우에는 full scan 을 사용한다
인덱스에 사용된 컬럼이 where 절에서 <,> 등의 부등호로 작성된 경우 index range scan 을 사용한다.
explain plan for
select * from employees where employee_id > 190;
select * from table(dbms_xplan.display);
Plan hash value: 1781021061
-----------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 16 | 1104 | 2 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID BATCHED| EMPLOYEES | 16 | 1104 | 2 (0)| 00:00:01 |
|* 2 | INDEX RANGE SCAN | EMP_EMP_ID_PK | 16 | | 1 (0)| 00:00:01 |
-----------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("EMPLOYEE_ID">190)
- Index를 구성하는 컬럼만을 조회하는 경우와 모든 컬럼을 조회하는 경우
index를 사용할 때, index를 구성하는 컬럼만을 조회하는 경우와 모든 컬럼을 조회하는 경우 다른 실행계획을 보이기도 한다.
Q. (SH스키마) sales 테이블에서 prod_id 가 200미만인 정보들을 불러온다,
1) 모든 정보를 불러온다 2) prod_id 만을 불러온다.
## 1) 모든 컬럼을 조회하는 경우
explain plan for
select * from jobs where job_id < 200;
select * from table(dbms_xplan.display);
Plan hash value: 944056911
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 33 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| JOBS | 1 | 33 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
## 2) 특정 컬럼만 조회하는 경우
explain plan for
select job_id from jobs where job_id < 200;
select * from table(dbms_xplan.display);
Plan hash value: 798070940
------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 1 (0)| 00:00:01 |
|* 1 | INDEX FULL SCAN | JOB_ID_PK | 1 | 8 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
- Index Full scan
Index full scan 은 첫번째 리프블록까지 수직적 탐색 후, 인덱스 전체를 탐색하는 방법이다.
주로 테이블에서 table full scan 의 부탐이 크거나 정렬작업을 생략하기 위해 사용한다.
Min/Max 를 구할 때는 인덱스의 시작, 끝 한번만 확인하고 1개의 블록만으로 결과를 낼 수 있다. (시험 출제)
explain plan for
select min(DEPARTMENT_ID) from employees;
select * from table(dbms_xplan.display);
Plan hash value: 613773769
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 3 | 1 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 3 | | |
| 2 | INDEX FULL SCAN (MIN/MAX)| EMP_DEPARTMENT_IX | 1 | 3 | 1 (0)| 00:00:01 |
------------------------------------------------------------------------------------------------
- Index Fast Full scan
Index fast full scan은 index full scan 보다 빠르다.
multi block read 가 가능하다.
데이터의 물리적인 저장순서대로 받아온다. 따라서 인덱스 정렬 순서로 출력되는 것이 아니다.
Index 에 없는 컬럼을 읽는 경우에는 Index fast full scan 을 사용할 수 없다.(시험 출제)
'SQLP' 카테고리의 다른 글
| [SQLP] 인덱스 성능 저하 요인 ★★★★★ (2) | 2024.08.06 |
|---|---|
| [SQLP] 옵티마이저 연산 (0) | 2024.08.04 |
| [SQLP] 인덱스 (INDEX) (0) | 2024.07.27 |
| [SQLP] Hint 실습 (0) | 2024.07.27 |
| [SQLP] Hint (1) | 2024.07.26 |